
At SEMICON West 2022, Heidi Van Ee and Darby Brown from the new Digital Solutions business at EMD Electronics spoke to Pete Singer, Editor-in-Chief of Semiconductor Digest about how data analytics is changing the conventional ways of controlling material quality in semiconductor manufacturing. Van Ee is Head of Use Case Execution of Operations Digital Solutions, and Brown is a Use Case Manager for Operations Digital Solutions. The two had earlier presented a talk “Data Analytics for Next-Gen Quality Control: How Machine Learning Can Enable Targeted Quality Control and Mitigate Process Change Risks.”
Q: Could you tell us basically what you do at the Digital Solutions business ?
Brown: EMD Electronics is a business of Merck KGaA, Darmstadt, Germany. We have three sectors: Electronics, Life Science and Healthcare. Digital Solutions is within our Electronics business.
We focus on scaling digital solutions to help our customers accelerate semiconductor innovation. At Digital Solutions, we’re a team of data scientists, data engineers, chemical engineers and business experts, and we work with quality control managers, product and process experts, and commercial managers — who own products within our portfolio to initiate and execute data science use cases. Each use case is meant to optimize a product, requires a seamless coordination of quality, R&D and supply chain operations primarily for operations, supply chain or new product ramp. I lead those use cases from initiation to productionalization, where we take the methodologies and the models we created and transfer them to the product owners.
Van Ee: My team is responsible for the data analytics on each of our use cases. The team is made up of Masters and PhD-level data scientists and chemical engineers, and the projects we work on range from using simple linear regression models to neural networks.
Q: In your presentation, you’re talking about a fairly big change in the industry where people are moving away from conventional certificate of analysis, more toward a data-driven approach. Can you explain why that move is taking place?
Van Ee: Conventional wisdom would tell us that as our materials are being used in advanced nodes, and as processes become more complex and yield targets more difficult to meet, the material purity needs to improve more and more. Impurities like trace metals, organic impurities and all variations need to be reduced. So, we have seen a push for CofA spec tightening as well as adding more and more parameters to the spec because of the fear of the unknown. All of this is making it more challenging to meet the specifications, and yet this may not even be important for the material performance. Instead, we need to use a data-based approach to identify what is most impactful to the performance of the material so we can focus our efforts on optimizing for this and not waste our time optimizing for something that is not impactful to the performance.

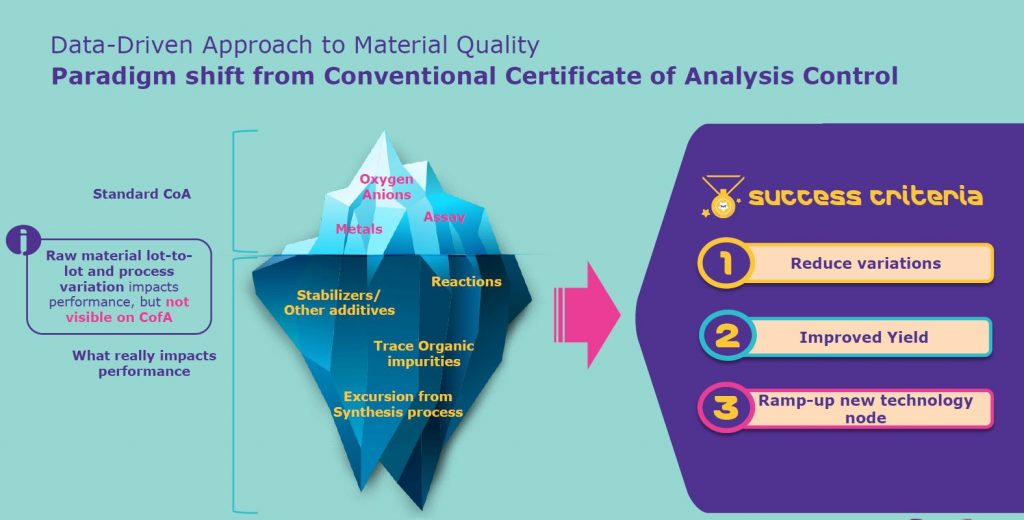
Brown: We have a pretty good example of that. Not too long ago, we were pulled into a project where a material was seeing performance issues at one of our customers during the ramp of a new technology node, and the team, using traditional investigative methods, really couldn’t identify what the difference was between this product that’s working really well at the customer and another product, which should be the same, but was having really poor performance. By working with the R&D team — in this case, looking at chromatogram data to characterize the material composition and using advanced analytics on that data — we were able to identify an impurity that was actually critical to material performance. If we had gone along with conventional wisdom and just assumed that the more we could shrink the presence of that impurity, the better, we actually would’ve seen a material failure and a stall to that product ramp.

Q: Okay, that’s fascinating — things can be too pure and not work as well. You mentioned multivariate analysis in your presentation. Can you explain a little bit more about why that’s important and how it works?
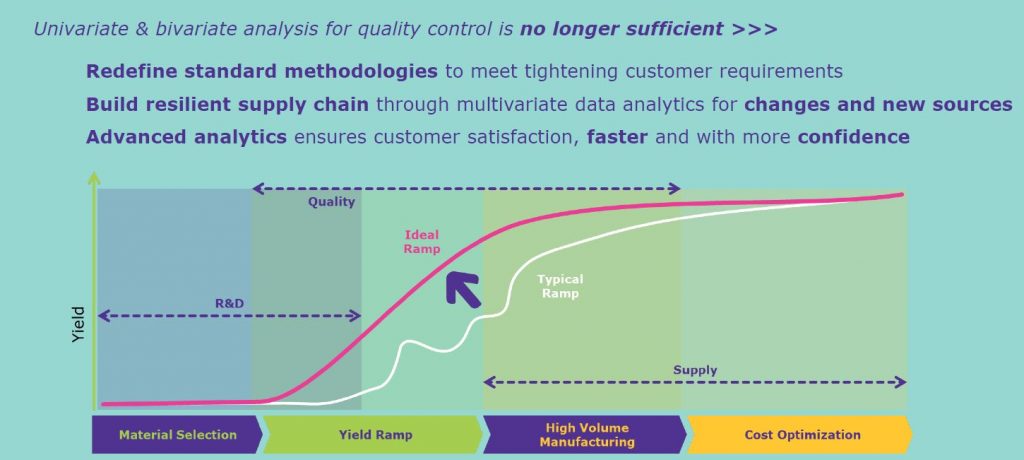
Van Ee: Multivariate statistics allow us to look for interaction effects between all parameters at once. Outliers or abnormal batches, which might not be detected by traditional univariate and bivariate analysis methods, can be identified early and any issues resolved before we ship product to the customer.
In our presentation we share an example where multivariate models helped us to understand interaction effects for one of our products. So, in addition to identifying outliers, we can use explainable models to improve our understanding of how the material works and how to control it better.

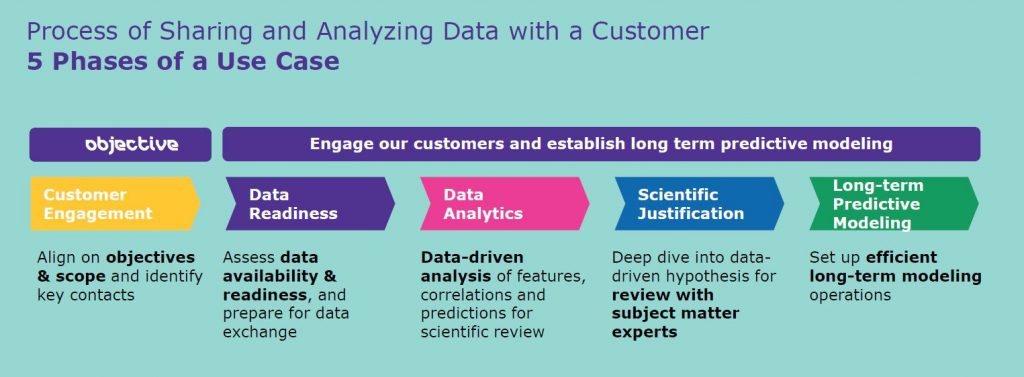
Q: What about long-term modeling? Where does that come into play?
Brown: Long-term predictive modeling refers to the stage in our project where we are taking the analytics methodologies and the models that we’ve created throughout that use case, and transferring that to the business so the product owners can also own the analytics long-term. This is critical for our process for a few reasons.
The first is that we can take this data-based approach and gain benefits from it not just during task force or a process change, but throughout the lifetime of that product so we can continuously improve internally.
The second is that we can provide enhanced service to our customers so we can really make them confident that their supply risk is low and if there are any upsets, we have the data to quantify what needs to change or what doesn’t need to change.
The third reason is that this allows us to scale. The industry needs widespread data-driven solutions. Therefore, our analytics approaches must become a service that our entire business can offer. Handing over the models and the analytics methods that we’ve created in a no-code, point-and-click manner to our subject matter experts empowers them long-term to provide this as a service to the customer and it frees our team up to tackle more products in our portfolio.
Q: How do you mitigate the change risk to your customer?
Van Ee: The long-term preventive control strategy that’s been deployed in production can be used to identify abnormalities or outliers when we have unknown or unanticipated changes in our process or the product quality, or if we’re introducing a change such as a process change or a new raw material. We can use advanced data analytics to strengthen our equivalency evaluations during our risk assessments, such as using unsupervised learning algorithms like principal component analysis when we don’t have customer data — or we can use proven predictive models with customer data. This can give us and our customers the confidence to proceed with the changes, knowing that the risk is low. In some cases, this may even mean that customers might opt for a paper qual, eliminating the need for in-fab tool testing of a qualification sample, and that can speed up the overall PCN approval process.
Q: And supply chains are really in the news today and supply chain responsiveness, especially. How does your approach enable you to analyze and develop solutions more rapidly?
Brown: You’re exactly right. Being responsive to our customers is critical for us. If, for example, we have a customer with an issue on their line and that issue might be because of a material issue, we need to respond to that as quickly as possible to minimize the impact on the fab.
To do that, first we really need to have the data in place that we can look at and analyze and understand from a holistic perspective what’s wrong. We aggregate our raw material quality control data, our process parameters and finished goods quality control data into one data set and have that pipeline automatically updating. If an issue arises, we can go to one place, get all of the information on that material and then start our analysis.
In addition to our internal data, it’s really important for us to have a relationship with our customer where they can share quantitative data with us on the performance of the material at their fab. The more information they can provide us about that performance — what’s good, what’s bad, and what’s in between — the easier it is for us to understand correlations between our material and their performance. That’s the first step.
The second step is to have our data scientists and our process/chemical engineers on retainer. These are people who have time to look into issues very quickly and come up with analytical results and data-informed suggestions or questions as to what’s going on. Then we also interface with our subject matter experts who can validate those data-backed hypotheses and make whatever changes are necessary to the process to improve the performance of that material.
Q: Can you tell me what your vision is of quality control in the future?
Van Ee: Our vision is to proactively use data analytics and machine learning to control the quality of our products and to identify what is most impactful to customer performance so we can work on reducing variations and improving customer yields.
Right now, we apply data analytics for our products that are in high volume manufacturing. Longer-term, we want to incorporate structured data collection at the earliest stages of product development. This will help us speed up the ramp of the product and provide better quality control over the lifetime of the product. Also, extending the multivariate data analysis approach to process changes will help us mitigate risks for the customer for both unintentional and intentional changes. Deploying predictive models in production for continuous quality control enables us to offer enhanced solutions to our customers to reduce their overall supply risk long term.
Interested in learning more? Check out Digital Solutions’ website.