VIJAY RAMACHANDRAN, Director of AI; JANAY CAMP, Ph.D., Technical Communications; and TOMMY HOLMES, Technical Communications at KLA Corporation., Milpitas, CA
Recently, Artificial Intelligence (AI) is spreading across many applications, essentially reinventing the way we think about computing [1]. But its rise was far from straightforward! The majority of the mathematical foundation for the AI revolution was already in place in the early 1990s. However, two factors delayed the rapid growth in AI that came about in 2010s. The first was the difficulty in collecting and processing large amounts of data. The second was computational power.
The evolution of AI (Figure 1) was aided in part by the strong development of semiconductor technology along the path laid out by Moore’s law. GPU and accelerator designs have begun harnessing more and more compute power made available by the raw semiconductor technology advancements. This increased compute power has resulted in the creation and subsequent pervasion of general purpose algorithms with widespread applicability across seemingly unrelated domains. However, applying these AI advancements to semiconductor industrial technologies is still in its infancy. The surest path to sustainable growth of both AI and semiconductors is to build mutually reinforcing pathways where advancement in one leads to acceleration of advancement in the other.


At KLA, we are working on several key strategic problems that need to be resolved to achieve this symbiosis. AI solutions need to be explainable and grounded in physics. They need to be computationally tractable. The challenges in applying AI solutions to massive sets of process control data in the semiconductor industry are big, but we believe that we can help move the industry past them.
Historical perspective
The advancement of AI to its current state has been far from smooth. There have been two major “AI Winters”, each lasting multiple decades, when most people had given up on it [2]. In order to understand the important role that our industry has in precluding a third AI Winter, it is important to understand the historical context of the previous two.
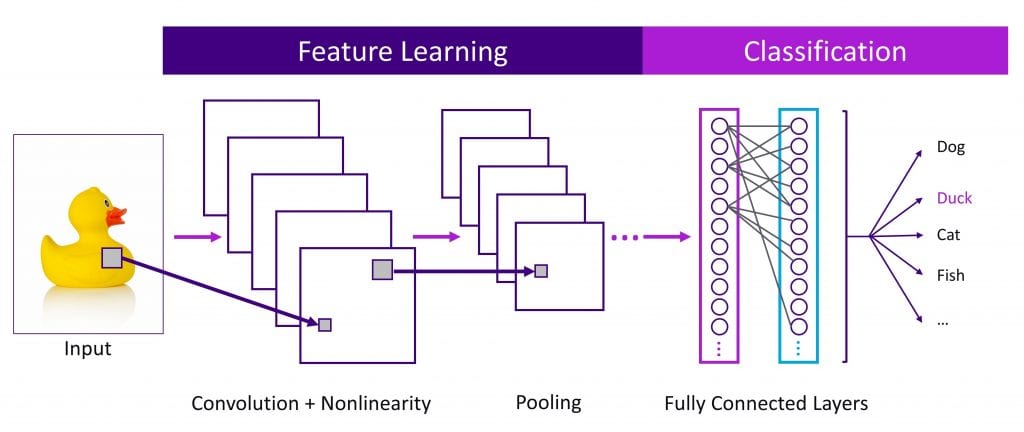
A good (albeit incomplete) view of this history may be narrated by looking at the elements of a simple Convolutional Neural Network (CNN) as generalized in Figure 2.

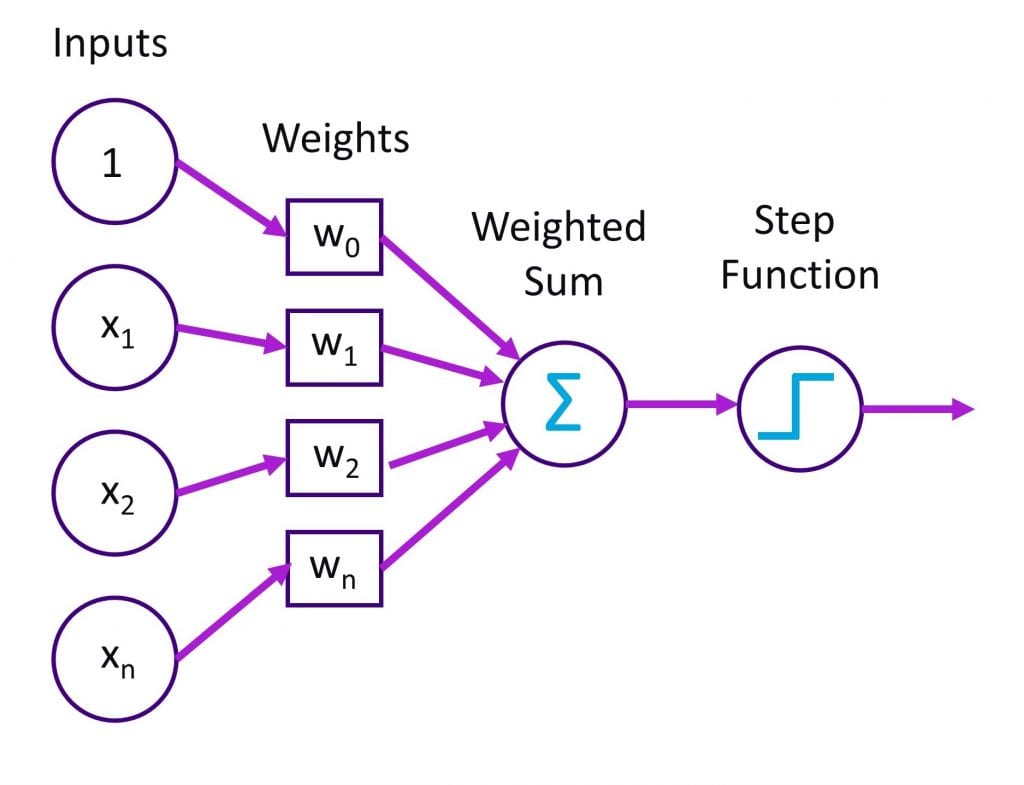
The simplest element of CNN is a node with three elements: multiple weighted inputs, an operation (convolution in the case of CNN) and finally an activation that results in classification. This idea originated as far back as the 50s [3] with the invention of the perceptron (Figure 3), the learning algorithm fundamental to AI, by Frank Rosenblatt at Cornell.

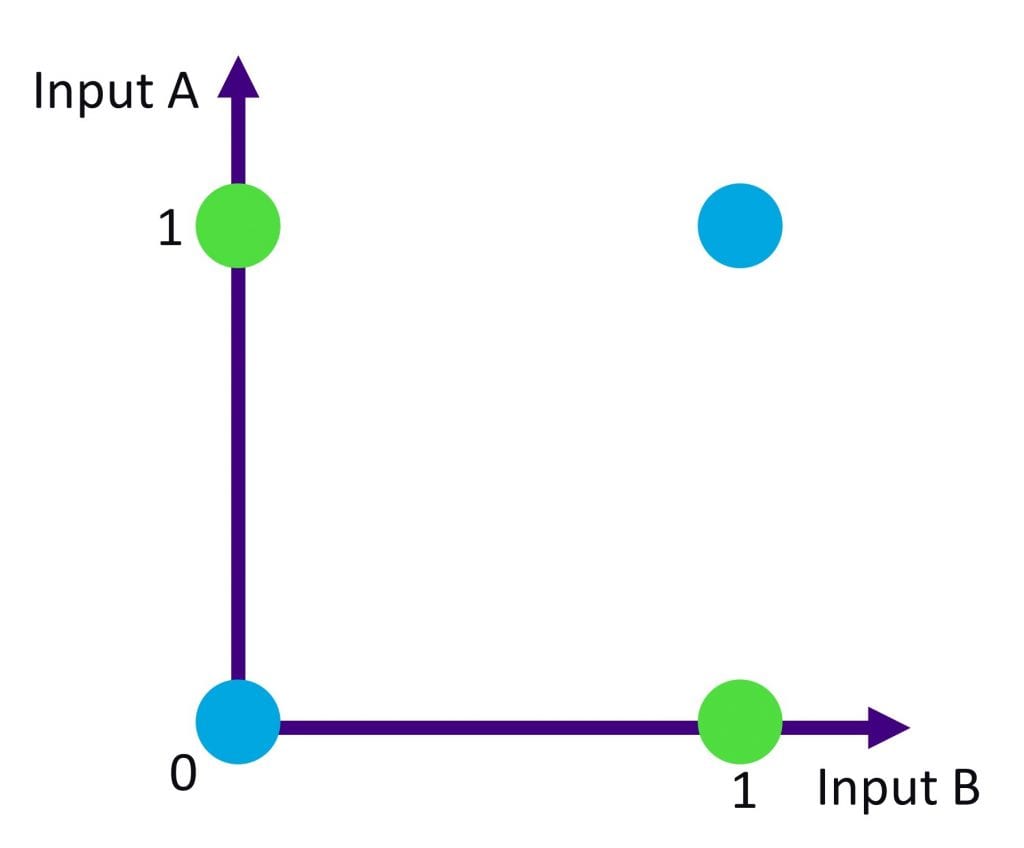
The idea that multiple perceptrons could be combined to solve complex problems set impossibly high expectations surrounding this “network” – formally called Artificial Neural Network (ANN). Rosenblatt himself said in an interview that perceptrons may “be fired to the planets as mechanical space explorers”[4]. However, the mathematical limitations of the ANN soon became well understood. A single “layer” of perceptrons acted as a linear classifier that could not even model simple non-linear mathematical functions! This breakdown can be illustrated by taking an XOR truth table — “exclusive or” where the output is true only when the inputs differ—on a graph as seen in Figure 4. Can you find a way to separate the blue and green dots using only one line?

The way to get around this was to move towards a non-linear, multi-layer approach. However, it was not clear at this time how weights for a multi-layer network with “hidden layers” would be updated. The disappointing performance of single layer ANN relative to the expectations started the first AI Winter in the early 60s. Researchers increasingly gave up on it and AI did not generate significant interest again until the mid-80s.
Ironically, many of the elements needed to get past the limitations of ANN were in fact happening in the middle of the winter. Some researchers realized that the problem of optimizing weights on hidden layers may be achieved by using a well-known construct from good old calculus: the chain rule. As early as 1970, Seppo Linainmaa outlined the idea of reverse automatic differentiation [5].
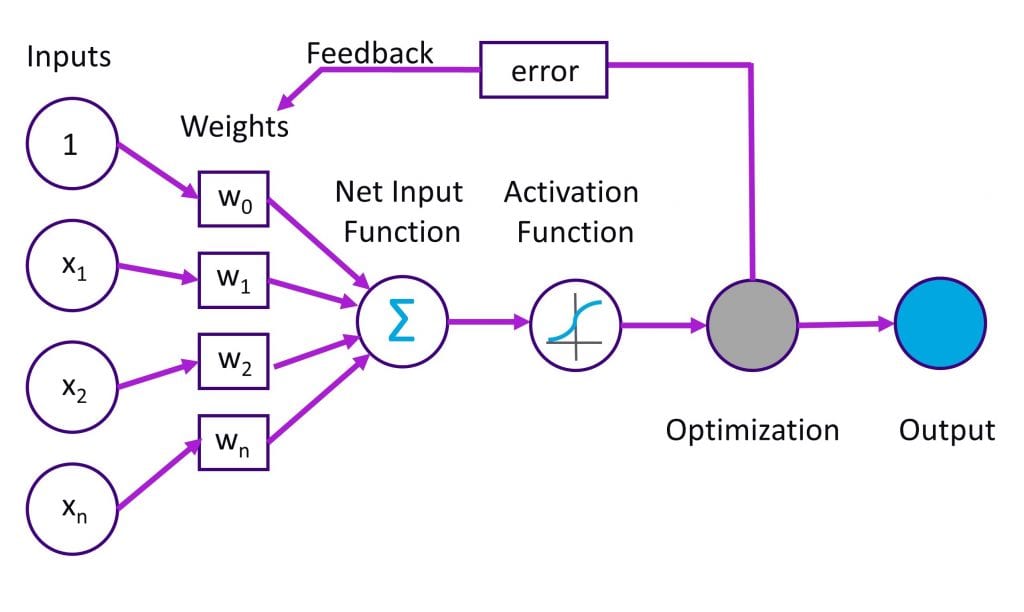
Paul Werbos outlined this solution more clearly in his 1974 PhD thesis [6]. However, the AI Winter was so strong that he did not even bother publishing this innovation as a standalone paper. It was not until 1982 that he finally published the central idea of using backpropagation to train a multi-level neural network (basic idea is shown in Figure 5). The clear mathematical framework and technique for widespread adoption of multi-level neural nets trained using backpropagation was presented in a 1984 paper by Rumelhart, Hinton, and Williams [7]. The first AI Winter had thawed.

The late 1980s saw development of exciting applications using neural networks, including handwriting recognition by Yan LaCunn et al. in 1989 [8]. The main breakthrough in this paper was the replacement of the simple linear operator with convolutions at the individual nodes. This drastically reduced the number of weights that needed to be trained to the size of the convolution filter. The concept of pooling was also introduced as a way of capturing information both locally and in larger contexts. This concept improved both the accuracy of the results and the computational efficiency.
However, as neural networks were being applied to harder problems, seemingly intractable problems started to emerge:
- The internet was not widely prevalent and acquiring and curating large amount of data was a non-trivial task.
- Compute budgets were still small compared to needs. While certain classes of problems were amenable to computationally efficient mechanisms like pooling, this was not generally true.
- Harder problems required bigger networks. Updating weights for a deep network often caused some of those weights to explode into large numbers, or conversely to vanish entirely. This “vanishing/exploding gradient” problem caused the resulting model to be very unstable and susceptible to even small jitter in input data.
Together, these problems caused the emergence of the second AI Winter in the early 1990s. During this time, computationally efficient models like SVM (Support Vector Machine) and Random Forest gained some traction, aided in part by breakthrough work by Yan LaCunn himself on characterizing SVM. Trevor Hastie and Robert Tibshirani at Stanford also did groundbreaking work in incorporating these modeling schemes into traditional statistical regression and classification techniques. “Machine Learning is Linear Regression that has a Marketing Department!,” Rob Tibshirani famously remarked.
The emergence of strong theoretical frameworks, combined with superior performance drove the emergence of what we now call Traditional Machine Learning (ML) methods (SVM, Random Forest, Classification and Regression Tree (CART), Gradient Boosting Decision Tree (GBDT)). These modelling techniques eclipsed neural nets to such an extent that Yan LaCunn and Geoff Hinton have both reflected on multiple forums about how their papers would get rejected just because they had the phrase “neural net” in their names.
Practitioners in AI have no doubt come across the CIFAR (Canadian Institute for Advanced Research) data sets. During the second AI Winter, CIFAR somehow managed to find funding for Geoff Hinton and Yan LaCunn and kept a small, but vibrant community alive. We owe them a huge debt, as there is a strong case to be made that they likely saved the field.
The rise of the internet and chip technologies whittled away at the data and compute problems surrounding neural nets, however, the vanishing/exploding gradients problem still remained. Geoff Hinton was again instrumental in achieving the breakthrough, with his paper titled “A Fast Learning Algorithm for Deep Belief Nets”[9]. Notwithstanding the emphasis on niche belief nets in the title, the paper’s main breakthrough was the discovery that clever initialization of weights in a neural network can get around the problem of vanishing/exploding gradients.
The final act that triggered the current explosion in interest around deep neural networks was the realization by Andrew Ng and others that while we could get better results by spending a lot of time and effort tinkering with network architectures, brute forcing the solution using very deep networks combined with previously untried amounts of training data provides a sustained path to innovation. Work by Ng and others led to breakthrough performance in “Google Translate” [1]. The deep neural networks improved upon decades of active research in the area using completely unsupervised learning, thus heralding the modern AI era.
AI has thus learnt to leverage advancements in chip technologies. If chip development can mutually take advantage of advancements in AI, it could create a self-sustaining system that could be the basis for solving very hard problems for a long time to come. The immediate question is: what are the challenges to building this virtuous cycle?
Semiconductor industry challenges and a call to action
AI has broad applications in the semiconductor industry. In the field of inspection and metrology, there are clear applications for regression, classification, reconstruction, denoising, inverse problem solving and several other key areas where AI provides breakthrough performance.
Stepping back from the particulars of use cases and technologies, the solutions in each case mentioned above have their origins in consumer applications. Adapting them for use in the semiconductor industry in particular, and for the broader category of “Industrial AI”, requires solving a number of critical problems. Three key problems are outlined here.
Grounding AI in Physics: Most semiconductor manufacturing techniques are based on deep understanding of the physics not only of the devices that are manufactured, but also of the tools that are used to manufacture and inspect those devices. Models learned purely from data run the risk of not being grounded in physical reality when they hit boundary conditions.
Amusing real life results in reinforcement learning illustrate this starkly:
- An AI for vacuum cleaner learns that the fastest way to finish the job is by committing suicide by falling down the stairs.
- An AI cheetah learns that the most efficient way to run is to use its head as an appendage.
When applied to industrial applications, these amusing anecdotes quickly become real life problems. Models need to be bounded and grounded in physical reality in order to avoid embarrassing and expensive mistakes. Sustained investment in new ideas for general purpose physics-based AI techniques are needed to resolve this problem.
Explainability, in the context of this note, means the extent to which the internal AI systems can be explained in human terms. For example, if a large end to end model is broken down into smaller models such that each “stage” is grounded in physical reality, then it is a more explainable system.
Although broadly related to the topic of interpretability that is gaining large interest in the wider AI community, the needs for the semiconductor industry will require additional work. The reason for this is that models are often used as part of wider control loops where humans make decisions based on model output. For example, the Statistical Process Control (SPC) for high volume manufacturing where humans make decisions based on defect data.
AI used in these settings need to provide not only an “answer” but all the relevant context that would explain why the answer turned out to be what it was. This emphasis on use of models for decision making is a niche area where practitioners of AI in the semiconductor industry should focus more attention.
Computational Challenges: Facebook generates four new petabytes of data every day [10]. While this seems like a lot, consider that a single flagship KLA broadband plasma defect inspection system generates just as much data every day. However, compute budgets are many orders of magnitude smaller. There is a clear need to be able to achieve exemplary results on shoestring compute budgets.
Several techniques such as multi stage inference and asymmetrical loss functions (that trade false positive performance for better false negative performance) are needed far more in Industrial AI than in mainstream applications of AI.
Tying it all together
The AI Revolution is in full swing. However, the history of AI clearly shows that nothing can be taken for granted. A resilient path to growth of AI would be for AI and the semiconductor industry to establish a cycle of mutually reinforcing improvements. Practitioners of AI in the semiconductor industry are in an exciting position to solve some very interesting problems in order to make this happen.
Sources
- Gideon Lewis-Kraus, “The Great AI Awakening,” New York Times, December 2016.
- Andrey Kurenkov, “Brief History of Neural Nets and Deep Learning,” December 2015.
- F. Rosenblatt, “The perceptron, a perceiving and recognizing automaton Project Para”, Cornell Aeronautical Laboratory, 1957.
- “New Navy Device Learns By Doing”, New York Times, July 8, 1958
- Seppo Linnainmaa, “Taylor Expansion of the Accumulated Rounding Error,” BIT Numerical Mathematics, 16 (2): 146–160, 1976.
- Paul J. Werbos, “Beyond regression: New tools for prediction and analysis in the behavioral sciences,” Ph.D. dissertation, Committee on Appl. Math., Harvard Univ., Cambridge, MA, November 1974.
- Rumelhart, Hinton, and Williams, “Learning representations by back-propogating errors,” Nature Vol. 323, October 1986.
- Yann LeCun et al., “Backpropagation Applied to Handwritten Zip Code Recognition,” Neural Computation 1, 541-551, 1989.
- Hinton, Osindero, and Teh, “A Fast Learning Algorithm for Deep Belief Nets,” Neural Computation 18, 1527–1554, 2006.
- Kit Smith, “53 Incredible Facebook Statistics and Facts,” Brandwatch, June 2019.