Moritz Brunion, Researcher Design-Technology Co-optimization, and James Myers, Program Director System Technology Co-optimization, imec
In the rapidly evolving field of cloud computing, maximizing computational resources within physical and power constraints has become paramount. Cloud providers, seek to optimize data center efficiency by designing powerful multi-core processors, often exceeding 100 CPU cores per chip, to serve numerous users concurrently. Such high-density designs allow for shared hardware resources, including network, memory, and storage, making every CPU a unit of rentable processing power.
However, the pursuit of scale and efficiency introduces a substantial bottleneck: while CPU and memory components continue to shrink with advances in semiconductor manufacturing, the network-on-chip (NoC)—responsible for routing data among CPUs and memory—remains stubbornly large due to scaling limitations in its long-range metal interconnects. As interconnects are scaled down, the resistance of the metal wires increases significantly, leading to higher power consumption and reduced performance when propagating long-range signals due to the need for additional signal repeaters. Additionally, the metal interconnects used for routing need to maintain a certain width and spacing to ensure reliable signal transmission and to avoid issues like crosstalk.

Previous approaches to reduce NoC area have encountered several challenges. Techniques like routerless designs and optimized router architectures, while effective in minimizing area, often require workload-specific optimizations to maintain scalability. This approach can improve performance for targeted workloads but limits adaptability in general-purpose systems like cloud computing, where specialization is less practical. Simplified topologies such as 2D mesh are widely used for their regular structure, but scaling core counts inherently increases worst-case communication latency. Throughput enhancements, such as widening channels or adding links, can mitigate this but often increase NoC resource demands, undermining the goal of area and cost reduction. Consequently, the NoC remains an area and cost bottleneck, restricting further reductions in chip size and efficiency.
In their latest IEDM paper, imec researchers employ a system-technology co-optimization approach to present two innovative approaches to scale NoC architectures: a dedicated NoC routing die, and backside NoC signal routing integrated into the BSPDN. Both strategies address the growing demand for high-bandwidth, efficient, and cost-effective NoC designs as chip architectures become increasingly complex. This article delves into the technical trade-offs and cost implications of these approaches, with a particular focus on backside NoC routing as a promising solution.
3D stacking as a NoC scaling booster
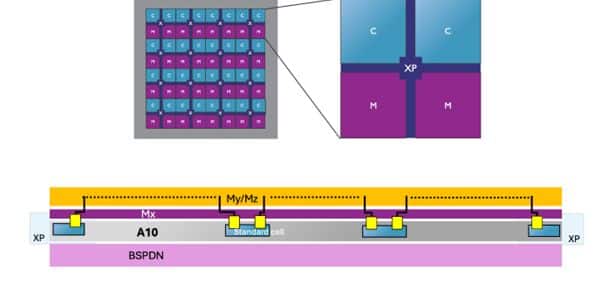
As a first scaling solution, the researchers disintegrated the NoC channel routes into a dedicated die separated from the high-density logic A10 layer. For this, they used wafer-to-wafer face-to-face hybrid bonding, which allows the NoC interconnects to achieve high die-to-die bandwidth with sub-micron pitch and low energy per bit. By moving the NoC routing to a secondary die, the designers can utilize a less advanced node (in this case N22) for the NoC channels. This approach not only helps to reduce manufacturing costs but also provides customization options for the back-end-of-line (BEOL) layers, allowing for fewer metal layers (2Mx3My instead of 3Mx6My), optimization of layer thickness, and simplified routing, all of which further reduce the cost of the NoC without compromising performance. Although the NoC channels are moved to the separate die, the NoC crosspoints or NoC routers responsible for making real-time routing decisions between the processing elements, are kept on the main logic die to ensure a low-latency connection.
Despite the benefits, the 3D-stacked NoC approach introduces some trade-offs. The additional die complicates power distribution due to the added power needs across the channels on the dedicated NoC die. Moreover, physical design experiments indicate an 8% and 15% increase in propagation delay and energy per bit, respectively, over the conventional 2D NoC reference.

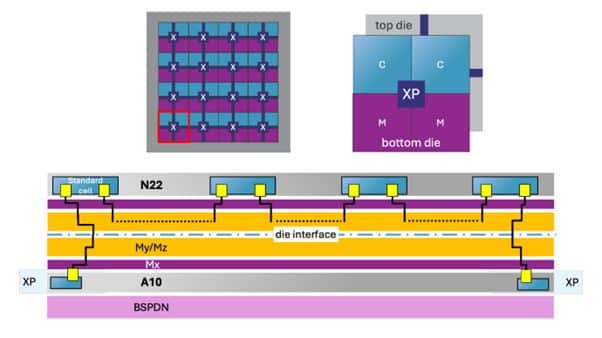
Back-end integration of the NoC routing channels
As an alternative solution, the imec researchers explored a different disintegration scheme adapting the back-end-of-line on the backside of the wafer to co-integrate the NoC channel routes alongside the existing backside power delivery network (BSPDN) to include. The BSPDN in the A10 technology uses metal layers optimized for power delivery, with thicker wires and wider pitches compared to the logic interconnect layers on the front side. Both the relaxed pitch and low resistance of the metal stack support the NoC’s requirements for efficient signal routing over long distances at high clock speeds.
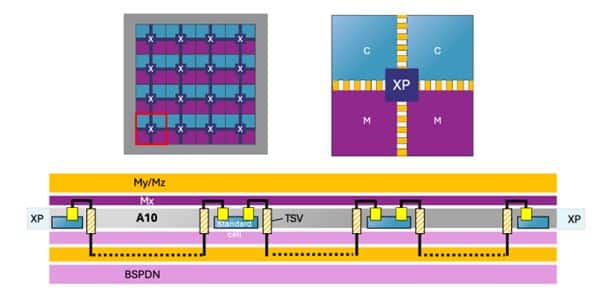
Still, integrating NoC channels within the BSPDN has presented multiple challenges, requiring innovative design adjustments. First, the researchers adopted a different wiring convention on the backside metal layers primarily to reduce area and costs associated with the additional metal layers required for NoC routing. In conventional routing architectures, horizontal and vertical connections are separated onto distinct layers, with each layer dedicated to routing in only one direction. Instead, imec proposes a bidirectional wiring scheme within the BSPDN layers, allowing both horizontal and vertical NoC channels on the same layer. This approach reduces the total number of backside metal layers needed for NoC routing, thereby reducing both the area and costs associated with the backside interconnects.
Secondly, because BSPDN currently lacks active devices on the backside, NoC repeaters must be placed on the front side in the logic layer where they can interface with the NoC channels routed on the backside. The repeaters were placed as ‘islands’ on the front-end with an optimized spacing interval and footprint to maintain signal strength as data travels along the NoC, reducing latency and ensuring stable data transfer. Although this approach may increase the complexity of routing signals back and forth, it ensures that the repeaters maintain high performance without disrupting the power grid on the backside, while also freeing up significant logic placement area on the frontside between these buffer islands.
Thirdly, when NoC channels are integrated into the BSPDN, they share space and routing resources with power distribution elements. This added complexity can increase IR (current × resistance, voltage) drop and reduce the effective voltage supplied to the circuitry, which can impact performance, stability, and efficiency. To counter this, additional ‘power assist’ routes were implemented at regular intervals to provide extra paths for power delivery, thereby reducing resistance in the network and minimizing voltage drop. This solution ensures that performance remains stable even as power distribution requirements become more complex.

NoC backside integration offers a cost-effective scaling solution
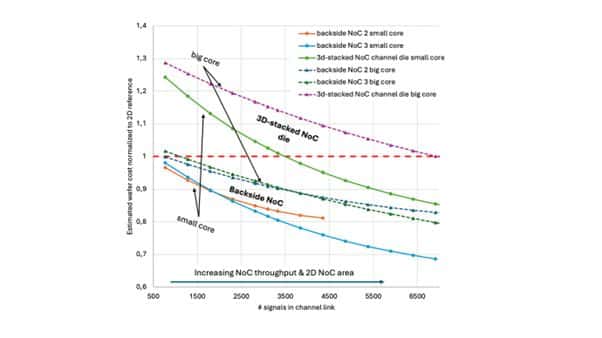
Evaluating both the dedicated die and the backside integration option for NoC scaling entails not only their technical trade-offs but also cost-effectiveness. Comparing the costs of each approach is essential to identify which solution offers the best balance of performance, scalability, and manufacturing efficiency as demand grows. The cost analysis conducted by the researchers shows that while both approaches offer cost benefits compared to the conventional 2D case, the backside integration method proves to be the more cost-effective solution.
The dedicated die approach is inherently more expensive because it involves creating a separate wafer for the NoC channel routing and bonding this separate wafer to the main processor die –a process that is more complex in 3D designs due to the need for both structural and electrical connectivity. In contrast, backside integration co-integrates the NoC channel routes alongside the existing backside power delivery network (BSPDN), which advanced CMOS foundries have already adopted as a key scaling booster for their nanosheet nodes. Adding two or three dedicated backside metal layers for NoC routing further reduces system costs by optimizing front-side area usage and minimizing the footprint needed for routing.
Its layout efficiency makes backside integration particularly advantageous as NoC channel width increases to meet continued scaling demands. As core counts per socket rise, especially in applications like cloud server CPUs, maintaining bandwidth and efficiently routing data to other cores becomes increasingly challenging. Backside integration provides the routing resources needed for wider NoC channels, reducing congestion, and enabling better data throughput while reducing the front-side silicon area increase and costs.
Future prospects for NoC scaling
The backside integration of NoC channels in semiconductor designs provides a powerful solution to improve routing efficiency and scalability. It highlights the strength of STCO principles, which facilitate the effective integration of BSPDN, backside metal layers, and logic components. This results in a more efficient overall design, particularly beneficial for high-performance applications like cloud server CPUs, where maintaining high bandwidth, efficient routing, and power scalability is critical.
While backside NoC integration is highly applicable for cloud server CPUs, its relevance to other applications, such as mobile devices and GPUs, is still being explored. The broader adoption of backside NoC integration depends on the evolution of Electronic Design Automation (EDA) tools. Currently, implementing backside NoC channels requires specialist flow interventions, but as EDA tools advance, they will likely streamline the design process, making this approach more accessible and standardized for a variety of applications.
Want to know more?
- The results on NoC scaling were presented at 2024 IEEE International Electron Devices Meeting (IEDM). Details can be found in the conference proceedings:
- Brunion M et al. System technology co-optimization of cost-bandwidth tradeoffs in Network on Chip through 3D integration and backside signals. Proceedings of the IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA.
- Learn more about how imec employs STCO to address system-level challenges in scaling https://www.imec-int.com/en/expertise/cmos-advanced/compute/cmos-scaling#stco
Biographies
Moritz Brunion received the M.Sc. degree in electrical and computer engineering from the University of Bremen, Germany, in 2022. He is currently a researcher at imec, Leuven, Belgium, and his research focuses on design-technology co-optimization for fine-grained 3D systems.
James Myers holds a MEng degree in Electrical and Electronic Engineering from Imperial College in London. He spent 15 years at Arm, leading research from low power circuits and systems, through printed electronics, to DTCO activities. He joined imec in 2022 to lead the System Technology Co-optimization program, with the aim of building upon established DTCO practices to overcome the numerous scaling challenges foreseen for future systems. James holds 60 US patents, has taped out 20 SoCs, has presented at ISSCC and VLSI Symposium, and has published in IEDM and Nature.